因为专业
所以领先
![[LOGO]](/template/default/image/logob.png)
![[LOGO]](/template/default/image/logoll.png)
因为专业
所以领先

近日,清华大学集成电路学院教授吴华强团队研制出一颗新型芯片,能高效“片上学习”不少人工智能任务。这颗芯片的核心元器件是“忆阻器”,架构是“存算一体”,创新点在于能耗只有常规系统的3%,研究水平很高,2023年9月14日在线发表在《科学》上。
美国芯片产业出口管制的背景下,芯片话题自带热度,清华的这个高水平芯片成果,引发了不少人的兴趣,希望看到中国芯片技术的新突破,但又感觉看不懂,这里我们需要关注“存算一体”、“忆阻器”以及“片上学习”这三个点,以及它们的协同一体化。
日常的编程,大多是在软件层面进行,其中“软硬件结合”、“嵌入式编程”指的是开发者能够对传感器、相机之类的硬件外设进行连接、SDK调用,但不需要知道硬件细节。
再深入,编程可以延伸到操作系统、指令集层面,这要求开发者对整个计算系统更为了解,用汇编语言之类的办法或者绕开普通编程与界面工具的限制,直接对系统进行深层调用,进而提高效率,但这还是在软件层面,思维都是基于0-1数值逻辑的。
继续深入,就涉及到到芯片层面。由于芯片和系统架构决定了计算系统的特性,有一定实力的公司会直接使用芯片进行开发,甚至自研复杂的芯片。目前阶段,制造芯片与传统IT产业01逻辑有区别,更像是一个在硅片上以纳米尺度绣花的物理化学过程,它的基础是半导体元器件。所以,芯片设计,是IT业真正“软硬兼修”的连接环节。它一头要理解指令集、操作系统、程序逻辑、人工智能等软件知识,一头又要和元器件、芯片架构等底层硬件知识打交道。
近年来,由于神经网络、深度学习的流行,业界在芯片设计层面对神经网络的研究也很热门。清华的忆阻器芯片,就是把以上各类知识综合到一起,深入理解之后的创新。在这个层面,如何存储、更新数据,都需要深入思索,并作出创新。
虽然忆阻器与交叉阵列展现了潜在的性能,但是要实际做出芯片应用,体现忆阻器的优点,还是个相当有挑战性的事——这需要对机器学习算法、系统架构、元器件设计、芯片设计、芯片制造都有相当的了解,才能做出完整的验证系统。而清华作者们就是具体实现了一个基于忆阻器交叉阵列的新架构芯片,能算是完全集成(fully integrated)的忆阻器芯片,并通过一系列人工智能任务上展现了芯片架构的优点与潜力。

清华团队开发的忆阻器芯片架构叫STELLAR,有两个忆阻器交叉阵列数组,大一些的是2T2R的,有1568*100个忆阻器,在神经网络模型中代表784*100的权重矩阵。小一些的是1T1R的,有100*20个忆阻器,代表100*10的权重矩阵(注意不是100*20)。两个忆阻器交叉阵列组合成了784*100*10的一个三层神经网络结构,用于完成一些小型的人工智能算法任务。
这两个Crossbar各有特性。大的是2T2R的,里面的权重是“off-chip”离线训练好的,然后上传到交叉阵列里面,它的特点是可以并行计算矩阵乘法,节点数多,展现了“存算一体”的优良特性。小的是1T1R的,规模小,但是后面附带权重更新逻辑,可以在芯片内训练更新网络权重,展现了“片上学习”(on-chip learning)的功能。

两个忆阻器交叉阵列结合CMOS芯片制造工艺,真的造出来了,上图是2T2R Crossbar的局部切片图。这个生产工艺良率接近100%,切片图像清晰。忆阻器元器件的制造应该不是难题了,材料也从二氧化钛变成了几种物质复合,元器件性能应该还有提升空间。
芯片上面也是有许多CMOS晶体管的,有辅助核心模块的周边电路,处理神经网络前向推导、反向传播学习的逻辑。还有ADC转换,将两个忆阻器交叉阵列的模拟物理量输出转换成数字。应用这颗芯片,其实就是用里面两个权重矩阵的推理与训练功能。
这芯片可以独立地作为一个神经网络运作,也可以在外面再加上一些层,作为网络的一部分。如实现CNN网络时,前面需要在外接电脑上实现一些卷积层,用这两个矩阵当最后的全连接层输出。
测试与训练时,需要外接的设备对这芯片传入数据、接收结果。整个测试体系搭建起来后,就是一个完整的系统,可以对芯片的性能进行完整的测试。测试的神经网络功能相对简单但能展现特性,例如,输出是10个节点,正好对应0-9的10个数字,可以用来测MINST数据集里的手写数字识别。
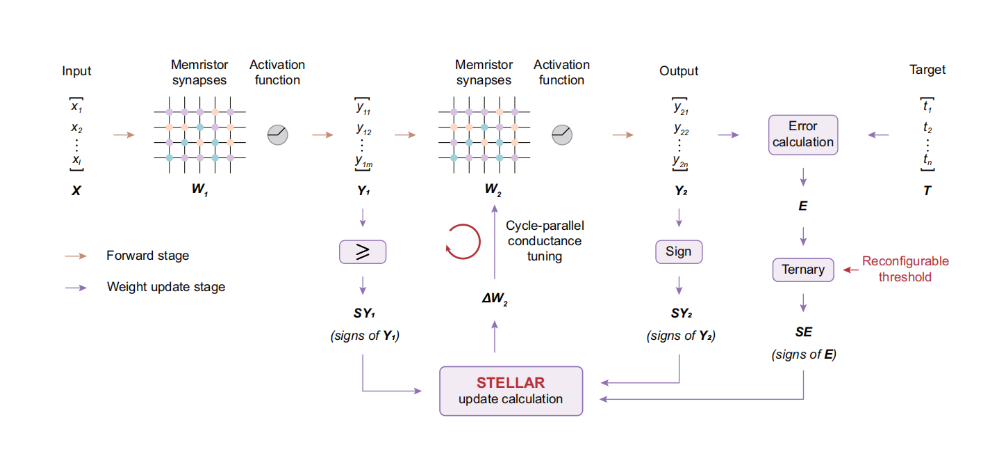
芯片架构叫STELLAR,是“sign- and threshold-based learning”的简称,指的是训练中的创新。如上图,W1是大的交叉阵列,输入向量X进来,乘以矩阵W1,再用激活函数(Activation function)ReLU变换——其实很简单,负数变0,正数不变——变成向量Y1。Y1再乘以矩阵W2,再ReLU变换,成为输出向量Y2。Y2与训练样本T比较,生成误差向量E。
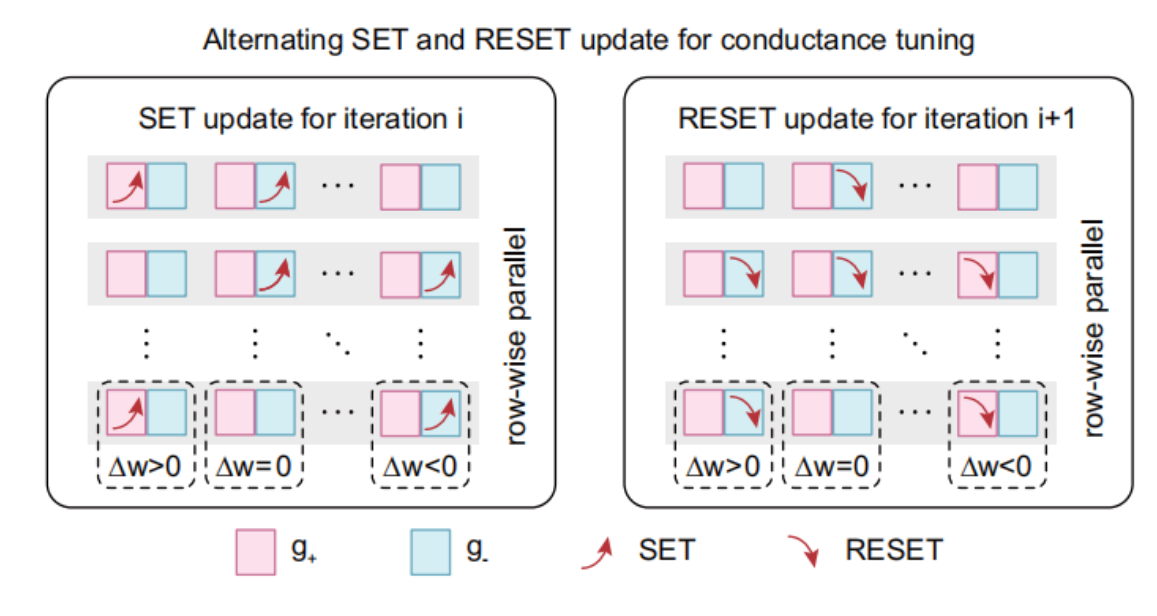
清华团队的创新是,对W2的训练,先将Y1、Y2、E三个向量的符号抽出来,实施更好的权重更新办法。其出发点是,一个权重是用一正一负两个忆阻器存储的,可以选择性根据符号,一列一起更新。这是深入思考反向传播的权重更新算法,结合元器件架构,实现了忆阻器潜在的并行功能。如图,权重更新分为SET和RESET两个步骤,SET步骤只对正的符号更新正Cell,对负的符号更新负Cell,而RESET正相反。这样SET和RESET分别都可以按列并行加速了。
另一个创新是,在误差向量E上加一个threshold,预先将一些微小的误差过滤掉,这样给出的符号向量,训练性能更优。这个threshold是可配置的,对不同的网络模型可以设置相应的过滤门限值,这应该是结合SET和RESET特性的进一步优化。

这个STELLAR架构,是为展现高效的片上学习功能。清华团队进行了多项测试,如追逐光点的运动小车。光点在前面一个车的尾灯上,后面的运动小车用摄像头拍前面的图像,用忆阻器芯片计算决定操控动作。夜晚的追光功能用CNN网络事先训练好了,前6个卷积层在PC上实现,后面512*100*10的两个全连接层权重转移到两个忆阻器交叉阵列上了。
实验表明,晚上跟尾灯表现不错。但是白天因为没训练,就追得不好。收集白天图像,对后一个1T1R的忆阻器交叉阵列进行“片上学习”。只要100次训练就有大幅提升,白天也能跟好了,同时晚上也还是能更好。
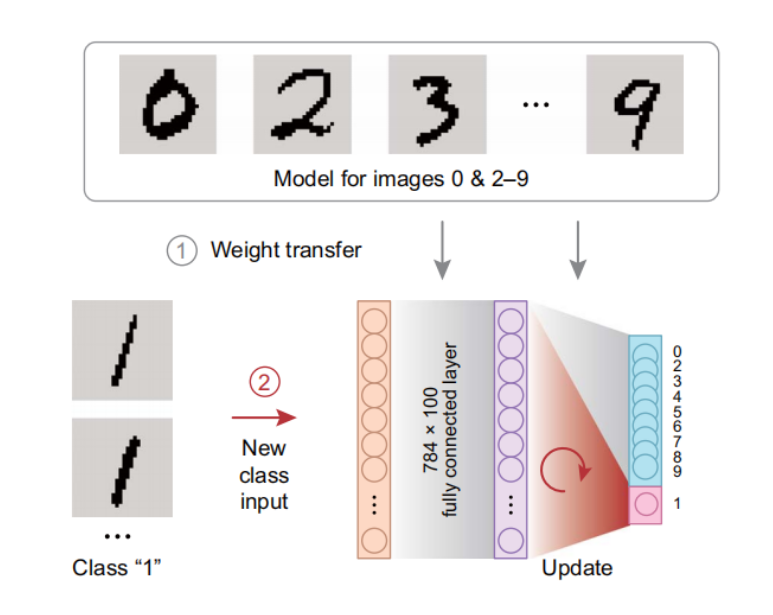
另一个实验是,事先将识别数字0、2-9的9个数字的网络训练好,784*100*10的网络权重转移到忆阻器芯片里(正好全用上了),故意不训练数字1。之后再把1的样本放上来,对后一个忆阻器交叉阵列进行训练,只要100个样本,1也能认了,识别率从7%提升到93%,老的数字识别率只是从95.3%微降到93.2%,这说明芯片能适应新类型的学习样本。
还有语音识别演示,女声提前训练好,男声在片上学习,也能学成。还通过ResNet网络的例子,展示了架构的可扩散性。这些人工智能任务,以及网络架构,按现在的深度学习进展来看,都是较为基础的(都还算是实用),但是用忆阻器芯片来演示展现特性,是文章的创新。
在字符识别测试时,清华团队还用48天进行了重复测试,结果是稳定的。这说明忆阻器芯片里的权重是稳定的,这是芯片能实用的重要特性。
可以看出,这颗忆阻器芯片是真的有“存算一体”的特性。矩阵权重就在芯片里,计算过程也是在芯片里完成的,而且还有神经形态处理器的仿生特性。
通过STELLAR架构并行加速等创新,相对专用集成电路(ASIC)加速的常规系统,清华团队实现了35倍的能耗效率,这是芯片架构的突出亮点。STELLAR架构里,不需要高能耗的write verification,在能耗效率上非常有优势。而且这是一颗相对完整独立的忆阻器芯片,较为系统地展示了忆阻器在神经网络计算方面的潜力,对于边缘计算有突破性意义。
通过以上的介绍,我们再看新闻通稿的内容,就会明白多了(以下为通稿原文):
● 全球首颗全系统集成的、支持高效片上学习(机器学习能在硬件端直接完成)的忆阻器存算一体芯片,在支持片上学习的忆阻器存算一体芯片领域取得重大突破。
● 该芯片有望促进人工智能、自动驾驶、可穿戴设备等领域发展。
● 芯片包含支持完整片上学习所必需的全部电路模块,成功完成图像分类、语音识别和控制任务等多种片上增量学习功能验证,展示出高适应性、高能效、高通用性、高准确率等特点,有效强化智能设备在实际应用场景下的学习适应能力。
● 相同任务下,该芯片实现片上学习的能耗仅为先进工艺下专用集成电路(ASIC)系统的3%,展现出卓越的能效优势,极具满足人工智能时代高算力需求的应用潜力,为突破冯·诺依曼传统计算架构下的能效瓶颈提供了一种创新发展路径。
通过以上的讨论也能看出,清华忆阻器芯片主要还是在性能探索层面,大规模进入工业实用还需要进一步优化。因为基于常规芯片的人工智能系统已经大规模应用了,深度学习取得突破后,识别性能相当好,一些应用成本很低。
目前来看,忆阻器芯片能够承载的网络规模还是有限,识别的准确率只是90%多,离100%还有不小的距离,和工业应用的高可靠性标准还是有点差距。一些复杂应用使用了规模很大的深度神经网络DNN,忆阻器交叉阵列只能在里面占部分环节,整个应用还是需要以传统的冯·诺依曼结构为基础。
也就是说,简单的神经网络应用,传统的架构已经够好,能耗和成本都够低。复杂的应用,传统架构是有“冯·诺依曼瓶颈”,能耗高很需要改进,忆阻器芯片现阶段还不足以在复杂应用中充分发挥作用。但是,忆阻器芯片确实展现出了并行加速与高效存储的特性,这让人很感兴趣,相信未来会有更多进展。




![[x]](/template/default/picture/closeimgfz1.svg)





![[x]](/template/default/picture/closeicon1.png)

![[→]](/template/default/picture/you.svg)









![[↓]](/template/default/image/xiangxiaimgfaz1-1.svg)




![[→]](/template/default/image/zixuniconim1.png)
![[x]](/template/default/image/closeicon1.png)

![[图标]](/template/default/picture/fc1c83eb02c951ce168aaebde4fd8205.svg)



![[↑]](/template/default/picture/rtxiangshangimg1.svg)